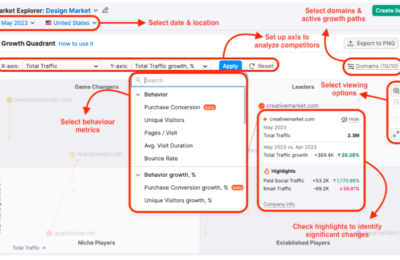
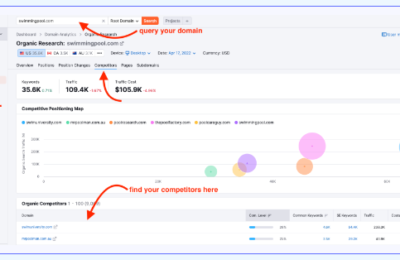
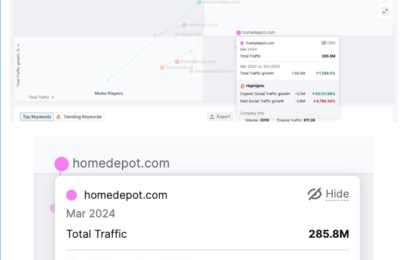
是否有办法了解竞品的网站规模大小,存在多少有效页面,从而进行更加详细的内容差距分析呢?
如果能够获得这些信息,就能够将自己与竞品的网站规模进行对比分析,了解与竞品网站之间的内容量差距,竞品在哪类内容上投入了更多的资源,以及竞品的网站架构是怎么样的,甚至还有机会洞察竞品的内容策略。
所有的这些洞察,前提都是先要获得竞品网站的所有有效页面URL,从更全局的角度来对比分析。
但是手动从竞品网站中逐个复制页面URL,肯定不是一个有效的解决方案。
因此,我们可以借助不同的工具,来快速整理出竞品网站的所有有效页面URL。
下面就介绍四种不同的方式,来实现这个目的。
01谷歌Site命令
在谷歌搜索中,使用Site命令,可以找到竞品网站中大量被收录的页面。
如下图所示(site: domain.com),谷歌会将查询网站中的收录页面罗列出来。
(使用Site命令找出目标网站被收录的页面)
这种方式最大的优势是:
- 免费
- 简单易用
- 快捷
而劣势也很明显:
- 页面数据不全(因为谷歌只收录了它觉得有价值的页面,因此并未包含所有页面)
- 导出数据不方便(虽然可以借助浏览器插件,例如SEOquake,来导出页面数据,但如果页面量级大的话,还是比较麻烦)
02XML Sitemap
第二种方式,则是直接从网站的站点地图中收集页面URL数据。
通常而言,我们会把网站中所有的重要页面都放到XML Sitemap中,方便搜索引擎抓取收录。
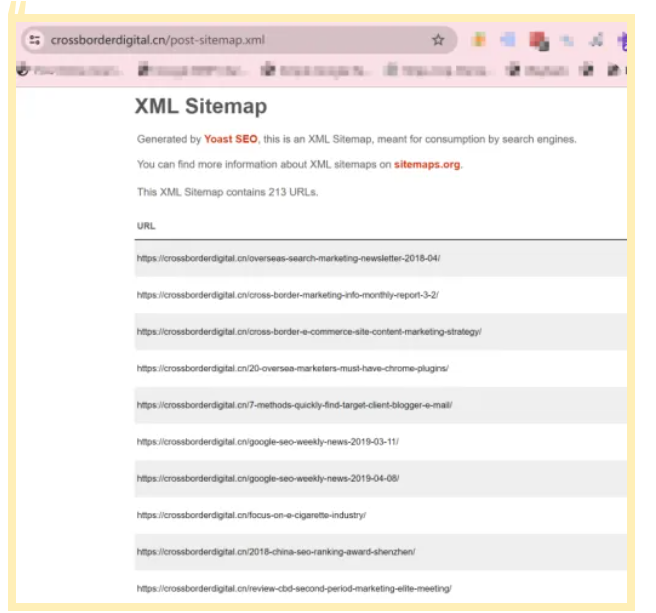
因此,通过提取XML Sitemap中的页面URL数据,我们可以快速且有效地实现这个目的。
默认网站的XML Sitemap会放在网站的根域名下,例如:https://www.domain.com/sitemap.xml。
如果在根域名下没找到的话,也可以到网站的robots.txt文件中找一下。
因为通常会在robots.txt文件中声明XML Sitemap所在的路径,来引导搜索引擎抓取站点地图。
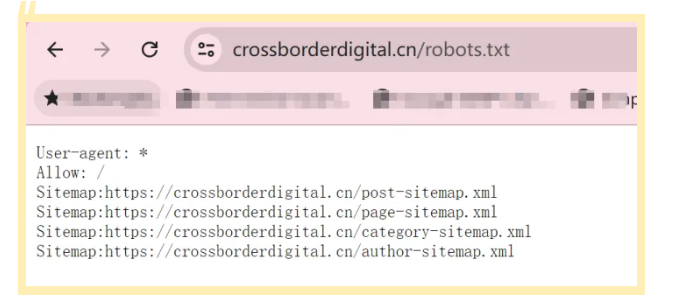
这样,我们就可以使用免费工具(例如https://www.searchant.co/sitemap-tool),来将XML Sitemap的页面URL快速提取出来了。
只需要输入竞品网站的XML Sitemap地址,等待片刻,就能直接导出页面URL数据。
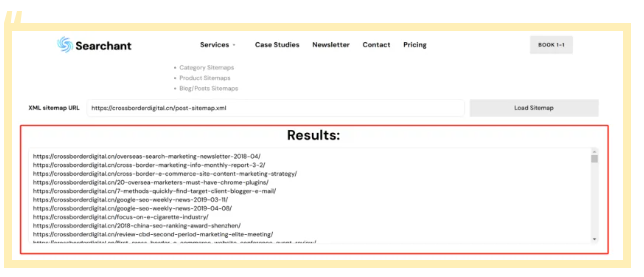
(使用Searchant来提取Sitemap中的页面URL)
这种方式的优势在于:
- 免费
- 方便快捷
- 获取到所有重要页面
而劣势则是:
- 需要竞品网站已生成XML Sitemap
- 且能够找到正确的XML Sitemap位置
03Screaming Frog
Screaming Frog(尖叫青蛙)是一款专门用来抓取网站页面数据的爬虫工具,非常强大,用它来抓取网站页面URL数据简直是轻而易举。
我们之前也专门写过一篇公众号文章:《Screaming Frog,让你尖叫着提升效率》,全方位的分享了我们是如何在SEO工作中使用Screaming Frog来抓取网站信息,提升效率的。
使用Screaming Frog来抓取网站页面URL非常简单,只需要在上方地址柆中输入竞品网站URL,等待它完成抓取,导出即可!

当然,如果觉得抓取整个网站太慢,也可以仅抓取XML Sitemap中的页面URL。
切换抓取模式为List Mode,然后将竞品网站的XML Sitemap地址粘贴进去,等待抓取完成。
这种方式的优势主要是:
- 方便快捷
- 抓取效率高
- 多种抓取方式可用
- 抓取到的网站页面URL完整
- 额外获得更多页面信息数据(例如Title,Description内容)
而劣势则是:
- 付费工具(折合约1800+RMB/年)
- 有一丢丢的学习成本
04 Semrush
通过在Semrush中创建专门的Project,并设置Site Audit后,也能找到竞品网站的所有页面URL。
等待Semrush抓取完所有页面后,我们就能够在Crawled Pages中,找到竞品的所有网站页面URL信息。
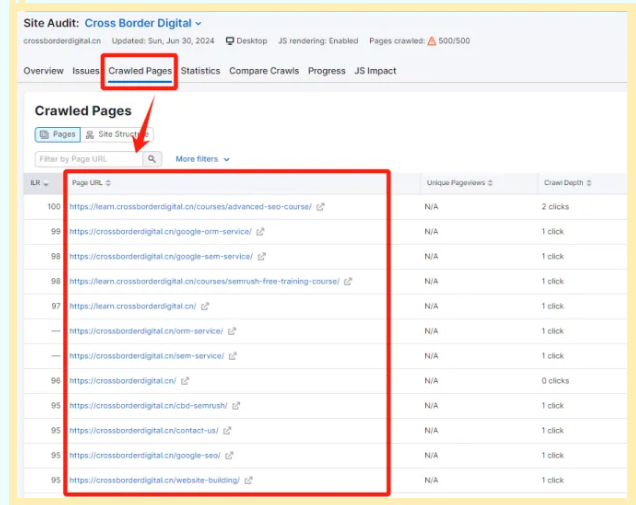
点击右上角的Export按钮,可以导出所有的页面URL数据。
使用Semrush的优势主要有:
- 方便快捷
- 抓取效率高
- 抓取到的网站页面URL完整
- 额外获得更多页面信息数据
而唯一劣势则是:
- 付费工具