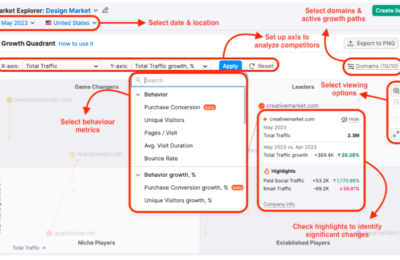
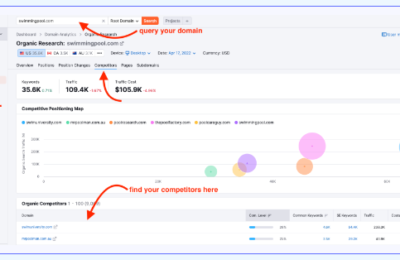
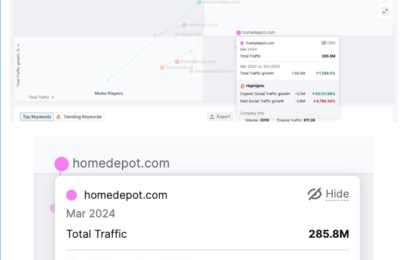
大家应该都知道,生成式AI是通过对大量数据进行学习和训练,从而具备内容生成能力(包括文字,图片,音频和视频)的机器学习模型,而这里的“大量数据”就包括我们的网站上的内容。
而随着各大公司推出自家的生成式AI后,很多站长可能会考虑的一个问题是:是否需要屏蔽AI Bot 来抓取自己网站的数据?
在回答这个问题之前,我们先来看一组数据(截止至2023年9月22日),网络上Top 1000 网站是如何应对这个问题的:
- Top 1000 站点中,25.9%的网站屏蔽了 GPTBot
- 其中非常知名的站点有 Pinterest,Amazon,Quora & Indeed
- 大部分的大型媒体/新闻站点都屏蔽了GPTBot,包括:NYTimes, TheGuardian, CNN, USAToday, BusinessInsider, Reuters, WashingtonPost, NPR, CBS, NBC, Bloomberg, CNBC, ESPN
而如下图是从2023.8月份至今,Top 1000 站点中屏蔽了 AI Bot 的网站数量,总体呈上升趋势。
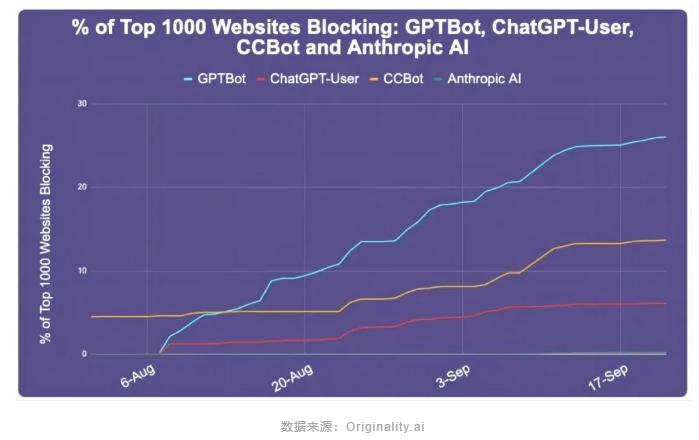
数据来源:Originality.ai
Top 1000 网站列表:https://dataforseo.com/free-seo-stats/top-1000-websites
我的网站是否应该屏蔽 AI Bot?
NO!至少对于绝大多数的品牌站和个人站来说,没必要!
那你可能会问,为什么这么多的大型网站要屏蔽AI Bot呢?我们认为,主要有三个原因:
1、屏蔽AI Bot 的这些大型网站多是属于大型资讯站或知识类站点,从网站属性的角度考虑,他们希望用户进入到自己的网站来浏览内容,而不是被生成式AI的生成内容抢走流量
2、这些大型网站并未从产商处获取到实际的利益
3、不想为各大厂商提供免费的数据来训练AI模型
为什么品牌站和个人站没必要屏蔽AI Bot?
对于品牌站和个人站而言,我们的目标是获取有效流量,最终促成转化。
随着各种生成式AI工具的功能迭代,以及其产商也必须考虑如何激励网站产出更多高质量的内容为其所用,因此很多生成式AI工具都会在其结果中标注或推荐内容来源页面,以便用户可以进入该页面做更进一步的调研,同时为这些来源页面背书。
比如Google Bard
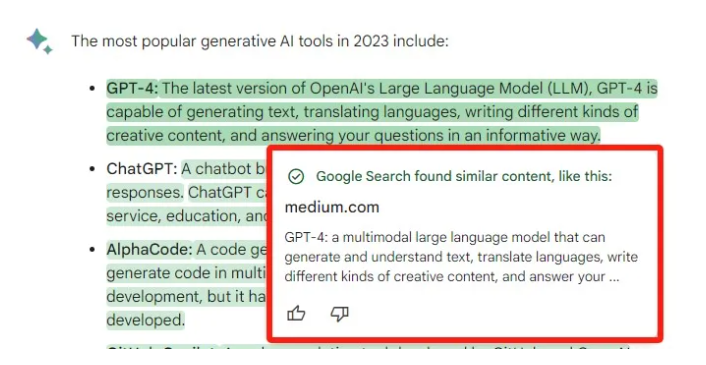
比如ChatGPT
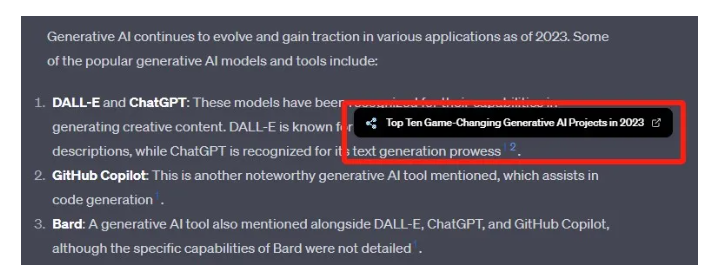
比如 Bing Chat
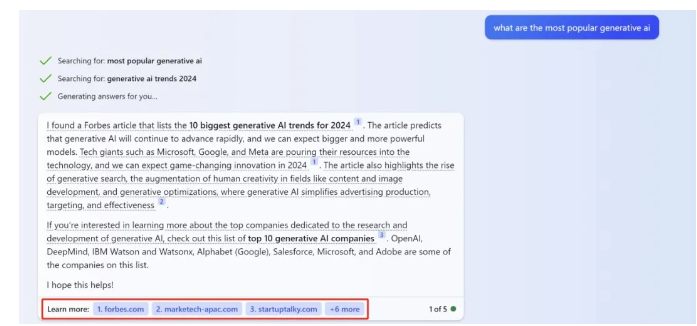
比如Google SGE
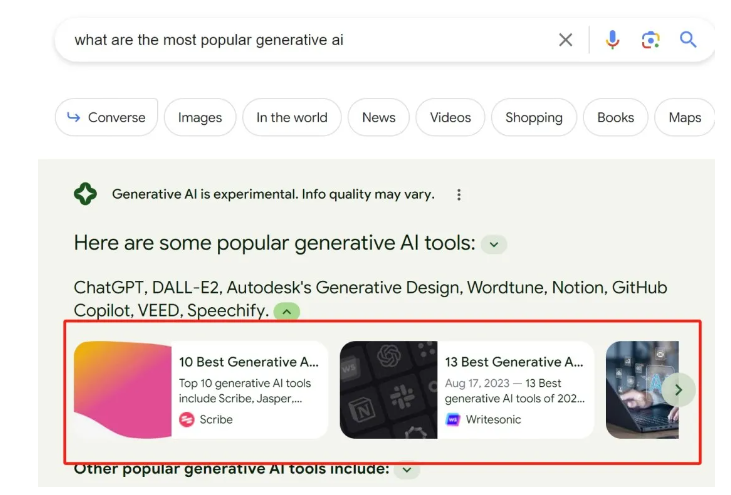
从本质上来讲,生成式AI能够成为我们的网站获取更多流量的新渠道。
所以,我们需要研究的是,如何能够让自己的内容更有可能出现在生成式AI结果中,被其引用。
与其恐惧变化,不如拥抱变化!
而且,随着生成式AI的越来越成熟,一定会有越来越多的工具会应用这些流行的机器学习模型,甚至直接调用它们的接口,应用在不同的垂直领域而大放异彩。
同时,这也意味着,不屏蔽AI Bot抓取网站,能让我们的内容有更大的可能出现在更多的阵地上!
如何屏蔽 AI Bot
当然,如果出于一些特别的考虑,你还是决定在自己的网站上屏蔽 AI Bot,也是有解决办法的。
由于AI Bot是会遵循网站 Robots.txt文件中的指令,来确定是否抓取网站中的数据,所以我们通过在Robots.txt文件中增加相应的 Disallow 命令来屏蔽AI Bot代理。
目前比较流行的AI Bot主要为 ChatGPT,Google Bard和 Claude,所以我们在此仅对如上三个AI Bot来示例如何屏蔽抓取。屏蔽ChatGPT的抓取
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /屏蔽 Google Bard的抓取
User-agent: Google-Extended
Disallow: /
Note: 如上指令会同时屏蔽 Google Bard 和 Vertex AI的抓取,Vertex AI 是Google 的机器学习平台,用于构建和部署基于人工智能的生成式搜索和聊天应用程序。
另外,屏蔽Google-Extended 这个代理并不包括Google SGE,因为Google SGE是Google Search的一部分,想要屏蔽Google SGE的话,必须得把 Googlebot 这个代理屏蔽掉(强烈建议不要屏蔽,这会导致整个网站不被Google抓取)。屏蔽 Claude的抓取
User-agent: Claude-Web
Disallow: /
当然,如果你想同时屏蔽如上三个AI Bot 的话,把上述代码全部粘贴至网站Robots.txt文件中即可