网站页面要在SERP中获得排名,其中的流程非常复杂,但总归分为三个环节:抓取(爬行和抓取页面HTML代码存入数据库);收录(对页面数据进行文字提取等预处理,存入索引库);排名(最后等待用户搜索关键词,页面才在SERP中呈现排名)。
网站收录对于网站能否获得排名至关重要,因此网站收录检查是所有网站运营人员日常工作的一部分。如何可以更加高效地进行检查工作,同时确保检查结果的正确性,本文分享了一些操作起来较为简单可行的办法。
方法要点:
1. 单个页面 直接用info命令/新版GSC查看是否被谷歌收录
2. 超过1000个页面的网站整站收录检查/快速检查多个新上线页面收录情况:Screaming Frog爬取网页快照,确定页面快照是否存在,来反推页面是否已被收录
- 使用Excel的VLOOKUP函数,匹配GA近期访问和整站Sitemap文件,筛选掉部分已被收录页面,得到未确认是否收录页面,为下面步骤提高效率
- 使用Excel的CONCATENATE函数,匹配快照命令+页面链接,直接批量生成网页快照链接
- Screaming Frog爬取确认网页快照,返回200码则已被收录,302码需要进一步检查(注意使用VPN,调整爬取速度,避免被谷歌block out)
- 对爬取结果返回302的页面进行检查
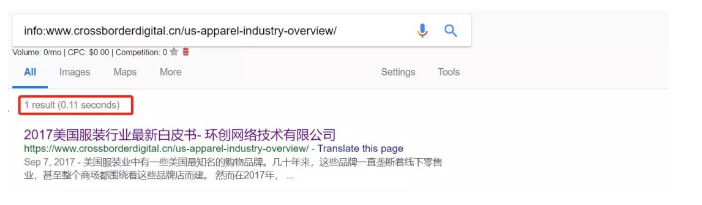
01 查看单个页面收录情况
如果单独查看某个页面是否被收录,可以用在谷歌搜索使用info命令,如info:www.crossborderdigital.cn/us-apparel-industry-overview/
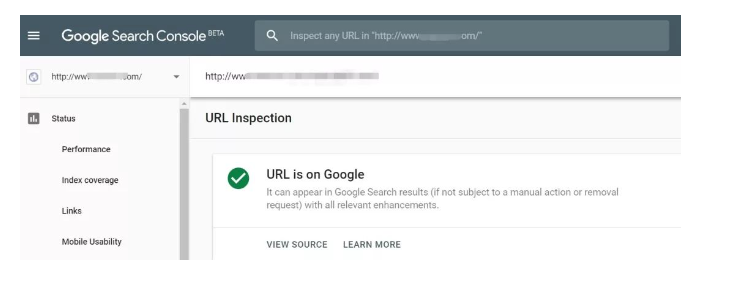
也可以通过新版google search console 的URL Inspection功能查看
02 批量查看页面收录情况
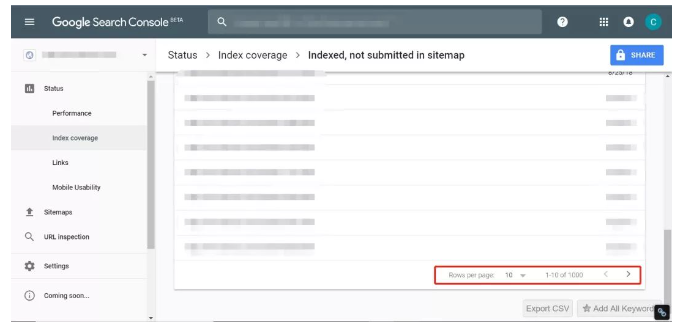
如果要检查整站页面收录情况,可以使用新版GSC 的index report,可以导出网站页面收录情况报告,方便检查哪些页面不被收录,但是只能导出1000个页面。
03 查看网站页面(>1000)收录情况
除了用GSC批量查看网站页面收录情况,还有一个替代方案是通过用Screaming Frog查cached页面Http状态,由于网页快照(cached)是搜索引擎在收录网页时对网页进行的备份,因此可以利用爬虫爬取该页面的数据来确认网页是否在搜索引擎中存有网页快照,确定是否被搜索引擎索引。
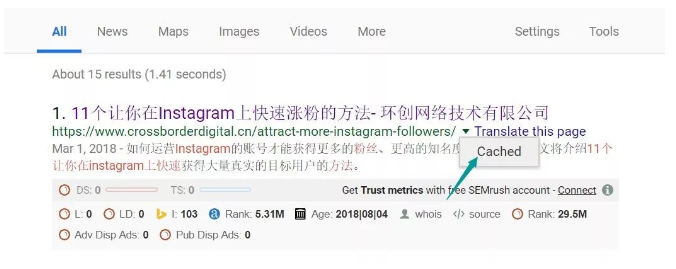
页面数量在1000以上的站点,或是只希望检查新页面收录情况的用户,可以尝试使用这个方案。以下为大家展示如何使用Screaming Frog批量检查页面收录情况。
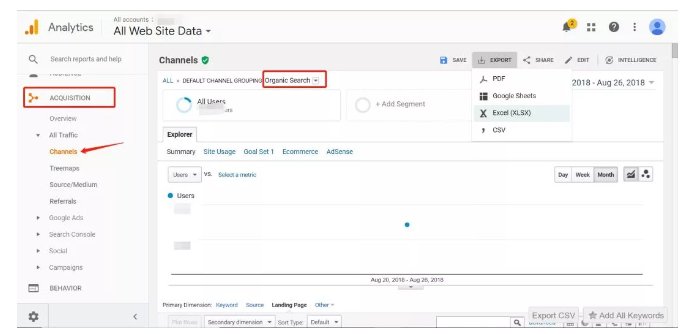
1. GA匹配sitemap筛选已被收录页面。
页面数量特别多的站点,可以先通过筛选掉部分已经确认被收录的页面,提高下面收录检查的效率。页面获得自然搜索流量,说明搜索引擎为用户展示了该页面。
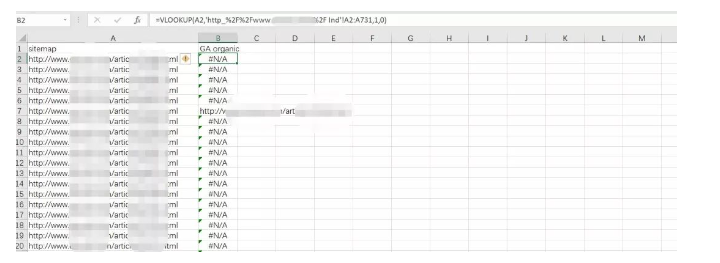
导出GA数据后使用VLOOKUP函数与网站sitemap进行匹配,筛选出近一个月未获得搜索流量的页面进行进一步的收录查询 (不会用Vlookup函数的小伙伴,可以在文章底部加小编微信获取模板)。
2. 批量生成谷歌网页快照链接。
上一步获得的页面清单,接下来用Screaming Frog爬取谷歌页面缓存的方式,来确认页面是否已被收录。
谷歌网页快照(cached)链接格式:
https://webcache.googleusercontent.com/search?q=cache:{URL},因此我们可以通过excel函数,批量生成页面谷歌快照链接。
3. Screaming Frog批量抓取链接状态。
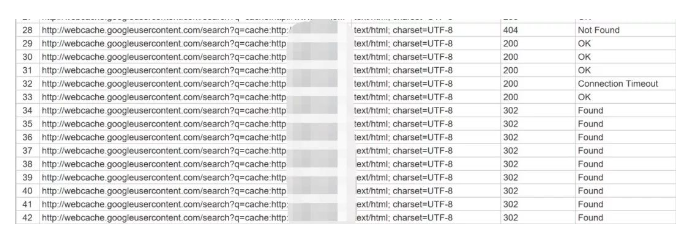
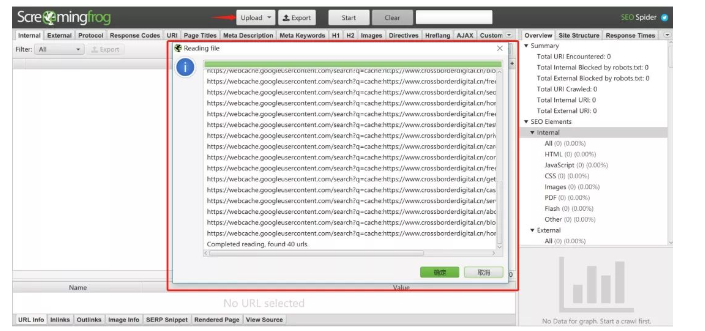
现在我们只需要通过Screaming Frog批量抓取这些链接状态,如果状态码返回200,则该页面成功被搜索引擎索引;如果是404,则说明未被索引。
打开Sreamingfrog, 点击Upload上传所有待检查链接,点击Start开始爬取页面信息:

注意:
由于我们现在是通过爬虫软件来抓取谷歌的搜索信息,IP地址极有可能被block out,因此在使用爬虫前,要注意使用VPN来操作,并且降低Screaming Frog爬取速度。
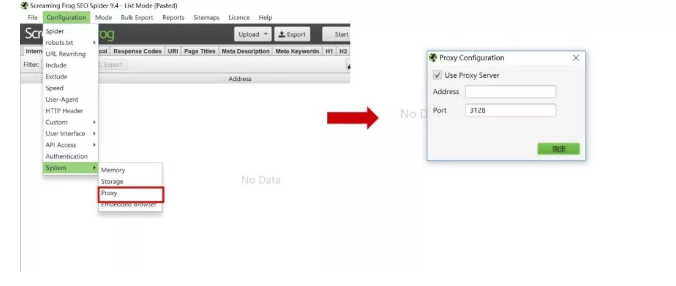
开启Screaming Frog上的代理:
Configuration>System>Proxy中点选“Use Proxy Server”
控制Screaming Frog的爬取速度:
4. 对爬取结果进行检查。
如果在爬取过程中都被返回302状态码,则很大可能被谷歌block out,需要调整爬行速度,更换VPN地区。如果仅有几个链接返回302状态码,则是谷歌需要对你进行人机识别,我们可以进行逐个查询。