今年,相信大家都被关于ChatGPT的各种帖子和新闻刷屏,话题讨论热度居高不下,甚至在互联网上引起了众多网友的争论。在ChatGPT出现之前,AI聊天机器人只能帮助人们搜索信息回答简单问题,对于复杂一些的问题,它们会说,“我好像不明白你在说什么”。ChatGPT颠覆了人们对聊天机器人的认知,特别是当用户使用的次数越多,ChatGPT进化更快,对于问题的回答更加的精细。

ChatGPT下面就由小编带大家来讲述ChatGPT的那些事儿,帮助大家快速了解ChatGPT概念以及使用。
01 基础概念
了解ChatGPT前,我们需要学习以下知识:
1.NLP自然语言处理(NPL)是研究人与计算机交互的语言问题的一门学科,处理自然语言的关键是要让计算机“理解”自然语言。与计算机编程语言不同,自然语言并不会被翻译成一组有限的数学运算集合。人类利用自然语言分享信息,而不会使用编程语言沟通,可通过NLP将它们翻译成机器指令。
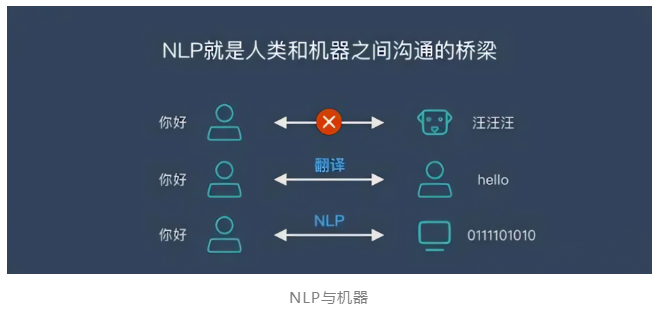
通过某种算法让计算机理解所输入的内容,这个过程中,输入的可能不是语音信号,也可以是键盘敲进去的,或者是用笔写上然后机器进行识别等等形式。所以,NLP又可以理解成→让机器理解。
2.ASR将语音信号转化成文字文本,并加以输出(显示在屏幕上面)。这个过程,机器并不知道你说的是什么,可以说就是单单的实现了两种信号的转化。而且概念本身就已经说明了,信号初始状态只能是语音信号,也就是人们说的话。所以ASR又可以理解为,让机器听见。
ASR和NLP存在着交集,但却是两个不同的领域。

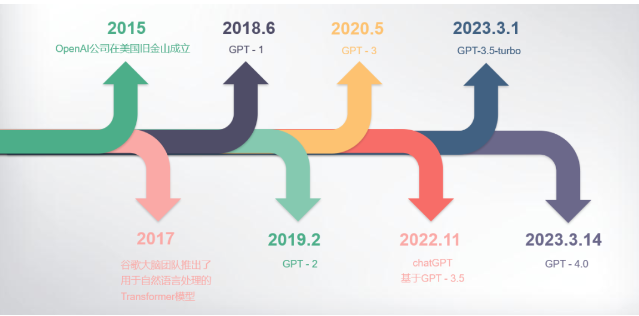
02ChatGPT发展历程
在早期,NLP 系统大都采用了基于规则的方法,之后是机器学习模型。机器学习模型需要特征工程,而特征工程又需要领域专业知识并且需要较长的时间,需要监督学习,但仍然需要人工标注。这时候需要Transformer 模型处理NLP和文本,使用自注意力机制记忆输入文本之间的关系来理解输入文本,有效率地捕获依赖关系。
机器翻译应用
GPT模型是一种基于Transformer的语言模型,使用自监督学习的技术,无需人工标注的数据,让模型在特定任务上自我学习和调整参数。其基本原理是使用大规模语料库进行预训练,再在特定任务上进行人工微调完成下游任务,从而得到对该任务的优化模型。

03 ChatGPT工作流程
1.预训练使用大量的文本数据对模型进行预训练,让模型学习自然语言的基本规律和语言结构。
2.微调根据实际应用场景,对预训练好的模型进行微调,以适应特定任务的需求。
3.接收输入接收用户输入的自然语言文本。
4.处理输入将输入的文本转换成模型可以理解的数字形式,并对其进行预处理和编码(token化)。
5.生成输出根据输入的文本和模型的预测,生成自然语言的输出,回答用户的问题或完成相应的任务。
6.不断优化
模型会根据用户的反馈和数据的更新不断进行优化,提高其生成文本的质量和准确性。
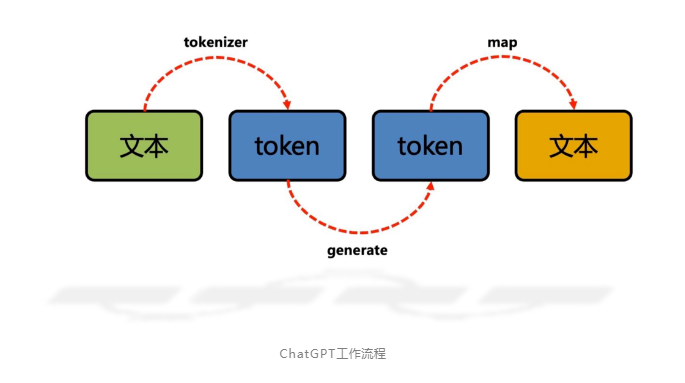
ChatGPT工作流程
04 如何使用ChatGPT
1.访问需通过科学上网,必须使用中国境外的线路,香港的也不行,亚洲的节点出现过大批量封号的情况,建议使用美国节点。
2.注册详细步骤可查阅公众号文章《如何优雅的注册和使用ChatGPT?》
1.ChatGPT3语言理解和生成能力可能相对较弱,在上下文处理、连贯性、回答质量和相关性方面可能需要更多的后处理和引导才能获得更好的结果。但ChatGPT 3作为较早版本,在特定的场景和简单的对话中仍然可用,并且更经济实惠。
2.ChatGPT3.5ChatGPT 3.5在性能和回答质量方面相较于3版本都表现出色,比ChatGPT4稍微差些,适合中等需求的用户。
3.ChatGPT4ChatGPT4 作为最新版本通常具有最先进的性能和回答质量,提供更准确、连贯、相关的回答。在多轮对话的持续上下文处理方面具有一定优势,能够更好地跟踪对话的上下文,使得对话更加自然流畅。
在选择适合自己的ChatGPT版本时,用户需要综合考虑性能需求、回答质量要求、预算限制等因素,并参考官方的定价政策做出决策。OpenAI提供了多种定价和计费选项,能够满足不同用户的需求。
最后
ChatGPT系列模型的不断发展和改进标志着自然语言处理技术的重要里程碑。这些模型的进步为我们提供了更先进、更智能的对话工具,为各种应用场景带来了便利和创新。随着模型的进一步突破和提升,我们可以预见到更加智能、自然流畅的对话体验。总的来说,我们可以期待ChatGPT系列模型将继续实现更大的突破和提升,为我们的日常生活和工作带来更多便利和创新。